
Discrete Compositional Representations as an Abstraction for Goal Conditioned Reinforcement Learning
Published in NeurIPS 2022
Recommended citation:Riashat Islam, Hongyu Zang, Anirudh Goyal, Alex Lamb, Kenji Kawaguchi, Xin Li, Romain Laroche, Yoshua Bengio, Remi Tachet des Combes: Discrete Factorial Representations as an Abstraction for Goal Conditioned Reinforcement Learning. NeurIPS 2022.
Paper link:Goal-conditioned reinforcement learning (RL) is a promising direction for training agents that are capable of solving multiple tasks and reach a diverse set of objectives. How to specify and ground these goals in such a way that we can both reliably reach goals during training as well as generalize to new goals during evaluation remains an open area of research. Defining goals in the space of noisy, high-dimensional sensory inputs is one possibility, yet this poses a challenge for training goal-conditioned agents, or even for generalization to novel goals. We propose to address this by learning compositional representations of goals and processing the resulting representation via a discretization bottleneck, for coarser specification of goals, through an approach we call DGRL. We show that discretizing outputs from goal encoders through a bottleneck can work well in goal-conditioned RL setups, by experimentally evaluating this method on tasks ranging from maze environments to complex robotic navigation and manipulation tasks. Additionally, we show a theoretical result which bounds the expected return for goals not observed during training, while still allowing for specifying goals with expressive combinatorial structure.
Compositional Representation in RL
In the cooperation of our lab, Mila, and MSR, we designed a novel DRL framework to address the issue of designing the goal of the agent for high-dimensional sensory inputs by learning factorial representations of goals and processing the resulting representation via a discretization bottleneck.
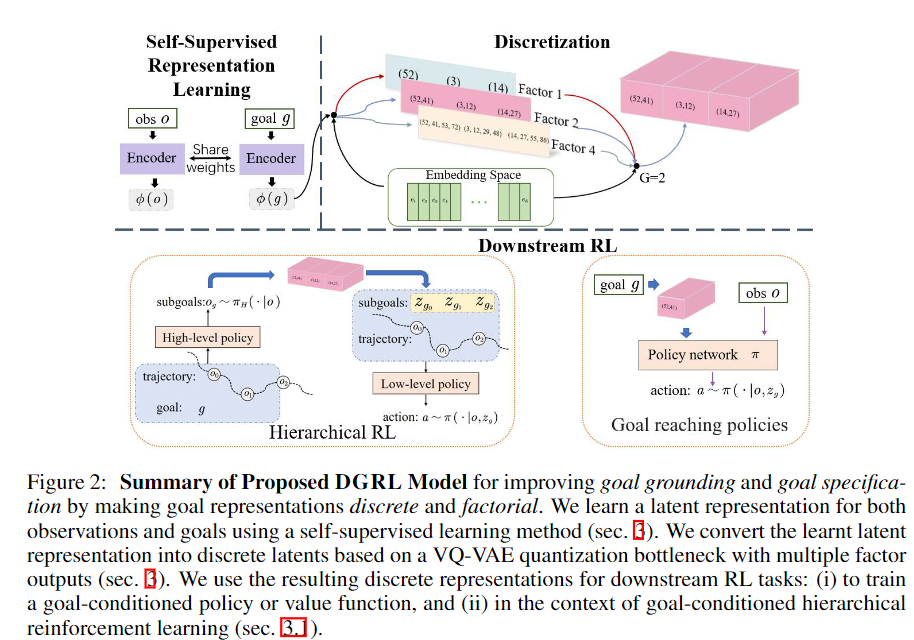
We first test our method in Color-MNIST dataset to support the idea that we can learn factorized or compositional representationsin. Color-MNIST example to demonstrate factorized representations; reconstructing the original images with two factors. Specifically, factor 1 tends to encode the shape of the digit, while factor 2 specialized in its color.

We demonstrate the ability of DGRL to learn factorial representations on real world robot data, where the robot arm moves in presence of background video distractors. We show an autoencoder trained with 8 discrete codes to reconstruct images of a real-robotic arm with independently changing distractors (TV and lamp). The top two rows show the reconstruction of the initial images. In the bottom left two rows, we change one of the discrete factors to match its value in the first image, in the resulting reconstruction, the lamp has turned orange. On the bottom right two rows, we change another discrete factor, to match its value from the first image, and observe that it made the robotic arm point left.

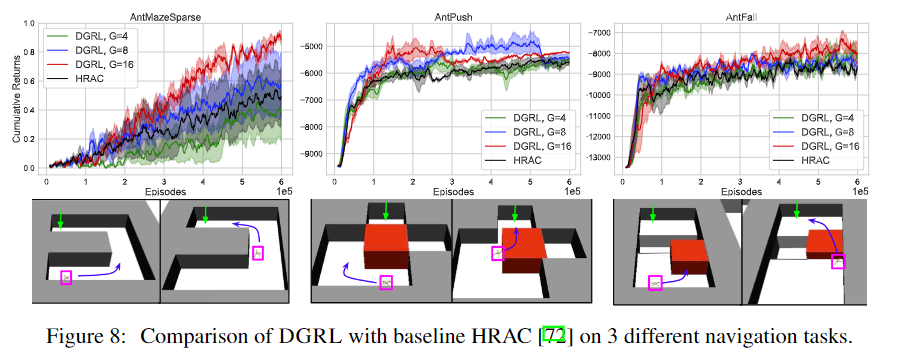
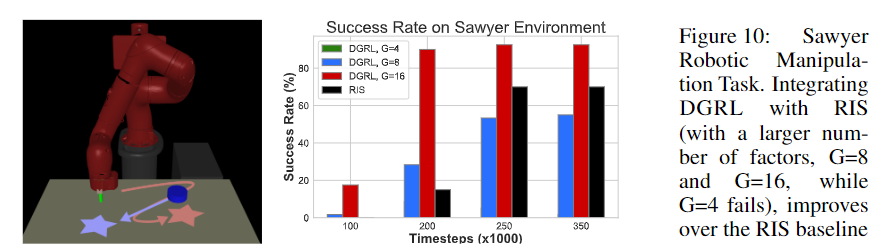
The experiment results show that DGRL improves the sample efficiency over the baseline methods.
Bibtex
@inproceedings{
islam2022discrete,
title={Discrete Compositional Representations as an Abstraction for Goal Conditioned Reinforcement Learning},
author={Riashat Islam and Hongyu Zang and Anirudh Goyal and Alex Lamb and Kenji Kawaguchi and Xin Li and Romain Laroche and Yoshua Bengio and Remi Tachet des Combes},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=N6zHSyChCF2}
}